Conventional security models prioritize preventing unauthorized access; governed autonomous execution must address a more insidious threat: authorized-looking execution derived from untrusted, manipulated, or semantically unsafe reasoning. A conventional security system asks whether a principal is authenticated and permitted to invoke an operation. Governed autonomous execution, by contrast, must verify whether a machine-generated intent is legitimate, contextually safe, bounded by policy, authorized by proof, and replayable after the fact.
Threat Model Principle
The control plane does not assume that the reasoning layer is malicious. It assumes something broader and more useful for security design: the reasoning layer is not authoritative.
This appendix establishes a threat model for the Autonomous State Control Plane. It maps the specific threat vectors arising when AI agents, external reasoning models, generated code, and dynamic policy engines interface with real-world infrastructure. Rather than cataloging generic AI risks, this model covers the transition path from initial reasoning to intent, policy, contract, identity, execution, evidence, replay, and protocol admission.
Scope and Assumptions
This threat model covers threats to AI-generated intent, the reasoning-to-execution boundary, context acquisition, policy evaluation, execution contracts, proof-derived execution identity, runtime execution adapters, evidence chains, replay and simulation, and generated-code admission. It supports the architecture described by Sovereign Agentic Loops, OpenKedge intent governance, Verifiable Agentic Infrastructure, Intent-to-Execution Evidence Chains, Protocol-Driven Development, replay, simulation, and audit.
Autonomy represents an authority-amplification surface: minor reasoning discrepancies, prompt injections, stale context inputs, or ambiguous contracts can propagate into material operational changes if model outputs translate directly into system execution. The control plane reduces this risk by ensuring that the reasoning layer generates proposals rather than authoritative actions.
This security framework operates under the following axioms: AI reasoning is inherently untrusted, external models reside outside the sovereign execution boundary, agents may be compromised or confused, and human operators are fallible. The architecture does not attempt to enforce perfect reasoning; instead, it confines the execution blast radius by enforcing deterministic boundaries external to the model.
This model does not guarantee model correctness, promise perfect prompt injection detection, or replace foundational cloud security. It defines the threats emerging at the intersection of autonomous reasoning and system mutation, and identifies architectural controls intended to prevent reasoning failures from becoming unbounded execution authority.
The primary assets requiring protection include sovereign execution authority, system state, policy definitions, execution contracts, short-lived credentials, and tamper-evident evidence logs. The core of this defense lies in protecting the authority boundary itself; flawed reasoning remains contained when the transition interface prevents unauthorized execution, maintains context freshness, and retains replayable evidence.
| Asset | Protection Goal |
|---|---|
| Execution authority | Prevent unauthorized or unjustified real-world mutation |
| Context data | Limit disclosure and prevent stale or manipulated decisions |
| Policy definitions | Preserve institutional rules and approval boundaries |
| Execution contracts | Ensure approved bounds cannot be widened or forged |
| Execution identity | Prevent misuse, reuse, or privilege expansion |
| Evidence chain | Preserve auditability, replayability, and accountability |
| Generated artifacts | Prevent unsafe code from entering operational workflows |
| Human approval authority | Prevent social, procedural, or system-level bypass |
The protected assets are interdependent. If context can be manipulated, policy decisions may be wrong. If contracts can be widened, identity may become overbroad. If identity is reusable, runtime execution may escape its task. If evidence can be omitted, replay cannot establish accountability. The control plane therefore treats the full governance path as the security surface.
Actors and Trust Boundaries
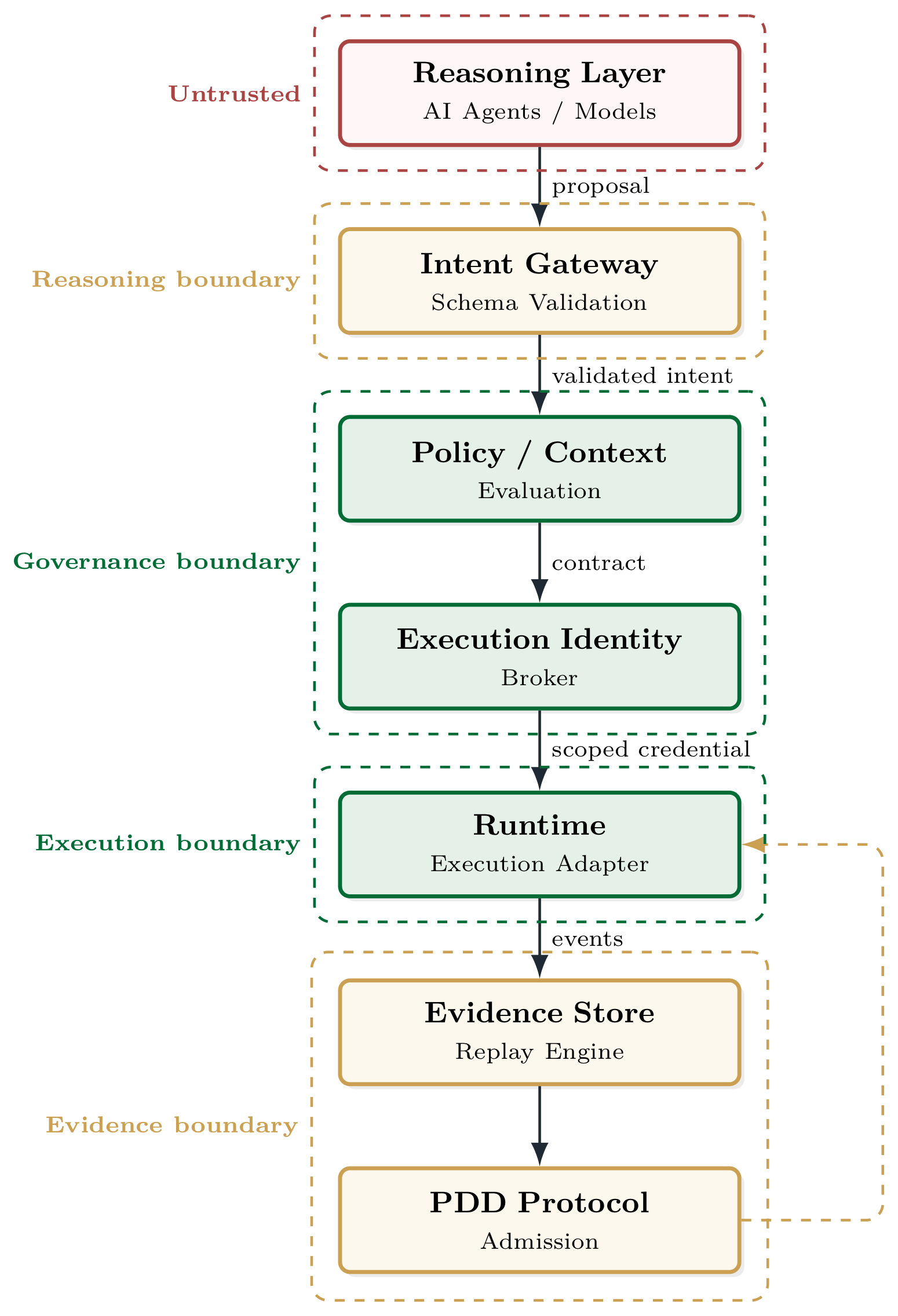
We model the system across multiple actors and distinct trust boundaries. The relevant actors include the external model provider, reasoning agents, user requestors, agent runtimes, intent gateways, context providers, policy engines, governance brokers, execution adapters, and evidence stores.
The model defines multiple trust boundaries:
- Reasoning boundary: external model output enters as a non-authoritative proposal.
- Intent boundary: model output becomes structured intent.
- Policy boundary: intent is evaluated under local policy and context.
- Identity boundary: execution authority is created.
- Execution boundary: actions affect real systems.
- Evidence boundary: events are recorded for replay and audit.
- Protocol admission boundary: generated artifacts become eligible for operational use.
The security of this architecture does not depend on agent compliance or model-level alignment. Instead, the control-plane components (the runtime adapter, identity broker, policy engine, and evidence store) must independently enforce boundaries, even when presented with a well-formed but unsafe intent proposal.
Threat Category 1: Reasoning-Layer Threats
Reasoning-layer threats emerge from prompt injections, tool-use manipulation, instruction hierarchy confusion, and hallucinated justifications. Sovereign Agentic Loops mitigate these vectors by treating all model outputs as non-authoritative proposals. Obfuscation membranes limit context exposure, structured intent validation sanitizes outputs, and policy evaluation is decoupled from the inference runtime. Model-neutral governance prevents single-provider dependencies from compromising the authorization path.
Threat Category 2: Intent-Layer Threats
Intent-layer threats arise when model outputs cross the governance boundary as candidate intents, manifesting as malformed intents, smuggled actions, scope inflation, or replayed requests. To neutralize these threats, the control plane enforces strict schema validation, risk categorization, temporal nonces, and context freshness verification before generating any execution contract.
The intent layer must reject ambiguity: if an objective is unclear, the scope is overbroad, or the requester is unauthenticated, the control plane escalates, constrains, or denies the intent rather than converting it into execution authority.
Threat Category 3: Context and Policy Threats
Context and policy threats occur when governance decisions rely on stale, manipulated, or inconsistent inputs. Mitigating these vectors requires context provenance tracking, narrow freshness windows, policy versioning, and deny-by-default behavior on missing context. High-risk intents require real-time context revalidation immediately preceding execution.
Threat Category 4: Execution Contract Threats
Execution contract threats involve forgery, contract widening, or ambiguity. Because the contract constitutes the primary enforcement boundary, it must be cryptographically signed, immutable, and parameterized with explicit resource bounds and expiration times. If an action cannot be deterministically validated against the contract, the runtime adapter must block execution.
Threat Category 5: Execution Identity Threats
Execution identity threats attempt to exploit standing privileges, leaked credentials, or long-lived tokens. The identity broker must enforce proof-derived workload identity, issuing short-lived, task-scoped, and non-reusable tokens that are strictly bounded by the execution contract (EID ≼ K).
Standing Privilege
Standing privilege turns an agent error into reusable authority. Proof-derived execution identity limits authority to the validated intent, contract, and time window.
The identity broker must fail closed: any validation failure regarding the contract, decision, context, or evidence requirements must prevent authority issuance.
Threat Category 6: Runtime Execution Threats
Runtime execution threats target the physical mutation interface via adapter bypass, parameter substitution, or race conditions. The execution adapter constitutes a critical element of the trusted computing base (TCB); it must verify the contract at the point of execution, fail closed, enforce atomic rollback, and emit detailed runtime evidence.
Threat Category 7: Evidence and Replay Threats
Evidence and replay threats aim to obscure accountability through omission, tampering, or selective logging. To support compliance in high-consequence environments, the system should employ append-only, hash-chained logs that record rejections and escalations alongside successful executions, supporting replayability.
Threat Category 8: Generated Software Threats
Generated software threats occur when AI-synthesized adapters, policy modules, or tools introduce malicious behavior or subtle bugs. Protocol-Driven Development (PDD) mitigates these threats by treating code as a candidate artifact. Artifacts are admitted to operational environments only after verifying structural, behavioral, and operational invariants within sandbox and property-testing pipelines.
Generated adapters and policy modules deserve special scrutiny because they participate directly in the active governance path. An unsafe adapter or compromised policy module can completely bypass runtime contract enforcement.
Mitigation Matrix
Table 24 summarizes the primary architectural mitigations for each threat category.
| Threat Category | Primary Mitigations |
|---|---|
| Reasoning-layer threats | SAL, obfuscation membrane, intent isolation, no direct execution |
| Intent-layer threats | Intent schema validation, scope checks, risk classification, expiration |
| Context and policy threats | Context provenance, freshness checks, policy versioning, replay |
| Execution contract threats | Signed contracts, narrow bounds, expiration, revocation conditions |
| Execution identity threats | Proof-derived execution identity, short-lived credentials, no broader than contract |
| Runtime execution threats | Adapter enforcement, contract verification, fail-closed behavior |
| Evidence and replay threats | Append-only evidence, correlation ids, completeness checks, replay tests |
| Generated software threats | PDD, invariant checks, sandboxing, admission evidence, CI/CD gates |
The mitigations must be implemented as layered controls. A single mechanism is insufficient: intent validation without policy evaluation is incomplete, and contracts without proof-derived execution identity are vulnerable to standing privilege bypass. Evidence without replay remains mere logging, and PDD without runtime enforcement cannot govern post-admission execution.
Residual Risks
Residual risks, including misconfigured policies, human operator errors, insider threats, and physical infrastructure compromise, must be managed through defense-in-depth, recurring red-team exercises, and periodic replay drills. Mature deployments should treat threat modeling as a continuous feedback loop, using incident evidence and validation failures to refine policy and adapter designs.
High-consequence domains must implement domain-specific safety cases, continuous system simulations, and clear manual escalation pathways. The ultimate objective of threat modeling is not to claim absolute security, but to delineate where authority must be bounded, where evidence must be produced, and where human sovereignty must be explicitly retained.